Java에서의 Callabe과 Future 그리고 CompletableFuture를 이해하고, 테스트를 통해 성능차이를 직관적으로 보고자 한다.
- Java5 이전 Thread 정의 방식과 Runnable
- 디버깅을 통한 Callable의 구체적인 동작 이해
- CompletableFuture
Java가 비동기 프로그래밍을 제공하기 위해 어떠한 변화를 거쳤는지 파악하기 위해 위 목차 순대로 차근차근 정리해보고자 한다.
1. Java5 이전 Thread 정의 방식과 한계점
1.1 Thread 정의 및 실행
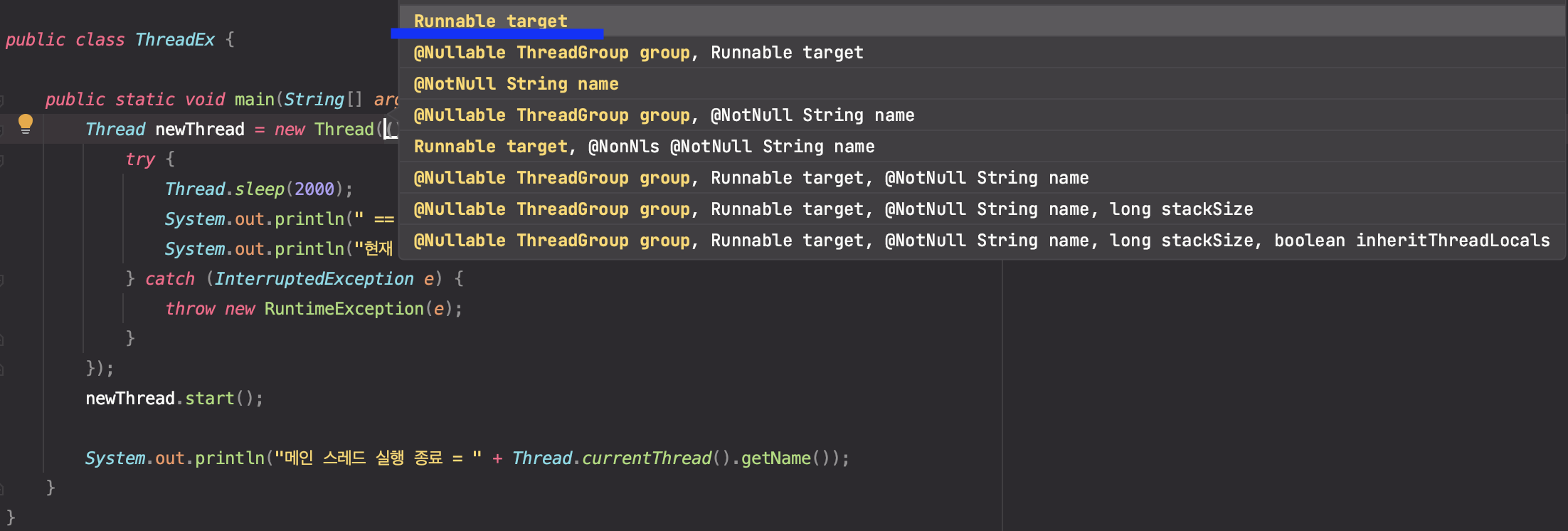
1public class ThreadEx { 2 3 public static void main(String[] args) { 4 Thread newThread = new Thread(() -> { 5 try { 6 Thread.sleep(2000); 7 System.out.println(" == 새로운 작업 정의 == "); 8 System.out.println("현재 스레드 = " + Thread.currentThread().getName()); 9 } catch (InterruptedException e) { 10 throw new RuntimeException(e); 11 } 12 }); 13 newThread.start(); 14 15 System.out.println("메인 스레드 실행 종료 = " + Thread.currentThread().getName()); 16 } 17}
- 실행 결과

new Thread()를 통해 스레드를 생성하고, 그 안에 람다식을 통해 새로운 작업을 정의하였다. 작업 내부에서 2초간 대기상태로 전환시키게 처리하고 실행 해보면 메인 스레드가 종료된 이후에 종료되는 것을 확인할 수 있다. 즉, 정상적으로 비동기 프로그래밍이 이루어진 것이다.
 그리고, new Thread() 내부에 람다로 정의한 타입이 바로 Runnbale 이다.
그리고, new Thread() 내부에 람다로 정의한 타입이 바로 Runnbale 이다.
1.2 Runnable Interface
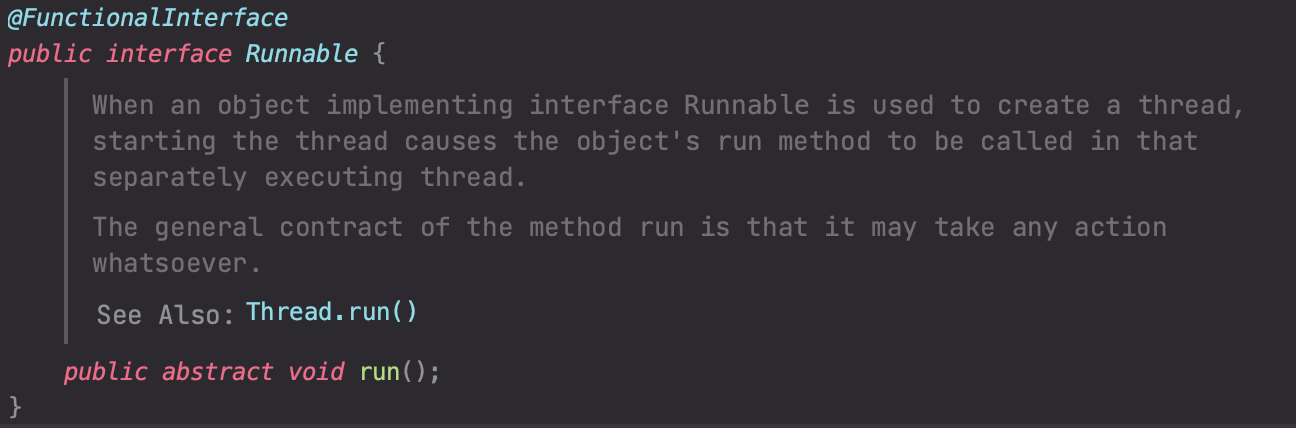
위 Runnable 인터페이스에 정의된 run()메서드에 대해 좀 더 알아보자.
위 Runnable 인터페이스에서 정의한 메서드는 run()이다. Thread클래스의 run()메서드가 이 Runnable 인터페이스를 상속 받아서 구현한 것이다. 여기서 중요한 점은 이 run()은 start()가 아니다. 지난 포스팅(Java 스레드 생명주기)에서 이야기 했듯이 스레드를 생성하는 것은 스레드 정의가 되었을 뿐, 아직 실행가능 상태(Runnable 상태)가 아니다. 즉, start()메서드를 통해 run()에서 정의한 작업이 Runnbale 상태가 되어 실행되는 것이다. 또한, 반환 타입이 void이다.
정리하면, Runnable 인터페이스는 run()메서드를 정의하며 결과를 반환하지 않는다.
+ 추가 한계점과 해결방법)
이 글에서 다루지는 않기 때문에, 이 글에서 적용되는 한계점은 아니지만 Thread&Runnable 조합은 애플리케이션 개발자가 직접 새로운 스레드를 정의하기 위해 사용하기에는 저수준의 API라고 볼 수 있다. 왜냐하면, 비동기 프로그래밍을 구현하기 위해 필요할 때 마다 새로운 스레드를 직접 생성해야하기 때문이다.
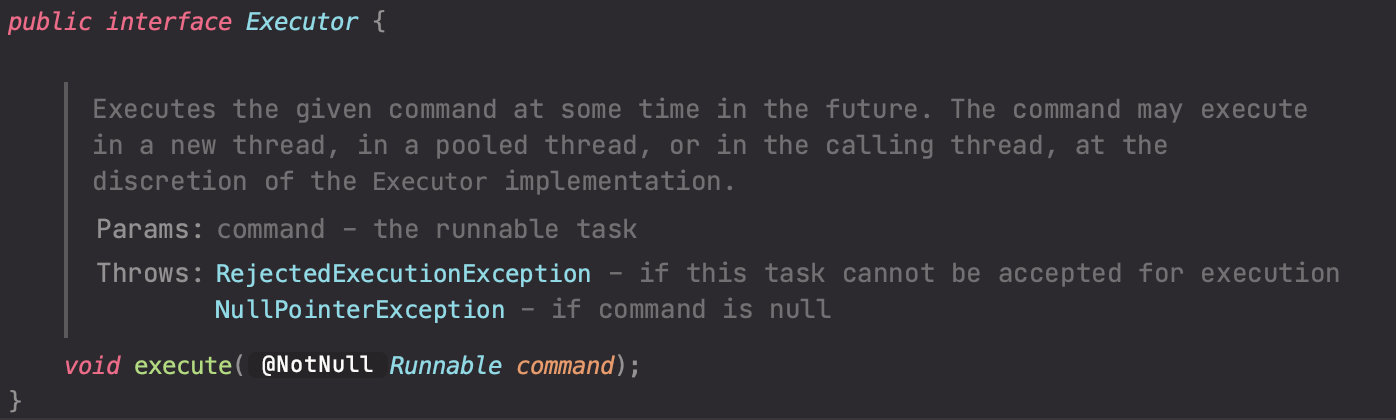
Java5 이후 스레드를 미리 만들어두고 재사용하는 스레드 풀 개념이 도입되었고 이를 적극 활용하기 위한 Executor 인터페이스라는 것이 등장했다. 이 인터페이스를 통해 스레드 풀을 구현하면, 스레드 생성과 실행을 분리할 수 있게 되며 Executor 인터페이스는 등록된 Runnable 작업을 실행하는 책임만 가진다. 즉, 개발자는 스레드 생성에 대한 고민을 하지않고 Runnable 타입의 객체만 전달하면 되며 Executor.execute() 메서드를 통해 작업을 실행한다.
2. Callable의 동작 이해 및 Runnable과의 차이
Java5 이전에는 Thread 클래스를 통해 Runnable 인터페이스를 직접 구현하며, 스레드를 직접 생성하고 실행해야 했다. 뿐만 아니라 반환값을 전달받을 수 없는 문제점이 있었다. 그래서, 이를 발전시킨 Callable이라는 인터페이스가 등장하였다. Callable은 제네릭을 통해 리턴 값을 받을 수 있다.
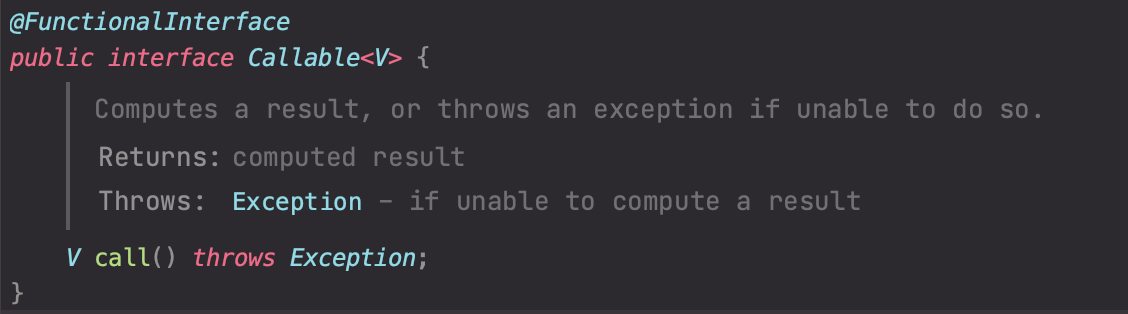
위에서 살펴본 Runnable과는 몇 가지 차이가 보인다. 제네릭 반환 타입이 있고, Exception 예외를 던질 수 있다.
2.1 Callable을 정의하는 방법
1public interface ExecutorService extends Executor { 2 3 void shutdwon(); 4 boolean isShutdown(); 5 boolean isTerminated(); 6 <T> Future<T> submit(Callable<T> task); 7 <T> Future<T> submit(Runnable task, T result); 8 Future<?> submit(Runnable task); 9 ... 10}
Callable은 ExecutorService라는 인터페이스를 통해 작업을 생성할 수 있다. ExecutorService는 스레드 풀을 관리하기 위해 많은 메서드를 제공하고, Executor를 상속받아 구현되었으므로 작업을 실행할 수도 있다. 이 중에서 submit()은 Callable 또는 Runnable을 사용해서 스레드의 작업을 정의하는 메서드이며, Callable로 정의하는 경우 Future라는 타입의 값을 반환한다.
위 ExecutorService 인터페이스에 정의된 submit()메서드들을 보자.
Runnable로 작업을 정의하면 반환값이 없거나 result라는 지정된 결과를 받아 Future에 저장한다. 그리고, Callable로 작업을 정의하는 submit()의 경우 Future에 값을 저장해서 리턴해준다.
그렇다면, Future는 어떤 녀석일까?
2.2 Future 구조와 원리
Runnable과 달리 Callable 인터페이스는 결과를 반환받을 수 있다. 그런데, 별도의 스레드에서 비동기로 실행되는 작업이 언제 종료될 지도 예측할 수 없다. 그렇다면 어떻게 비동기로 실행되는 작업에 대해서 결과값을 받을 수 있을까??
바로 미래에 결과값을 받는다는 의미에서 Future인 것이다. 다른 말로 하면 비동기 작업의 결과를 Future가 가지고 있는 것이다.
비동기로 실행되는 작업이 어떻게 Future에 저장되고, 어떻게 그 값을 받아오는지를 살펴보자.
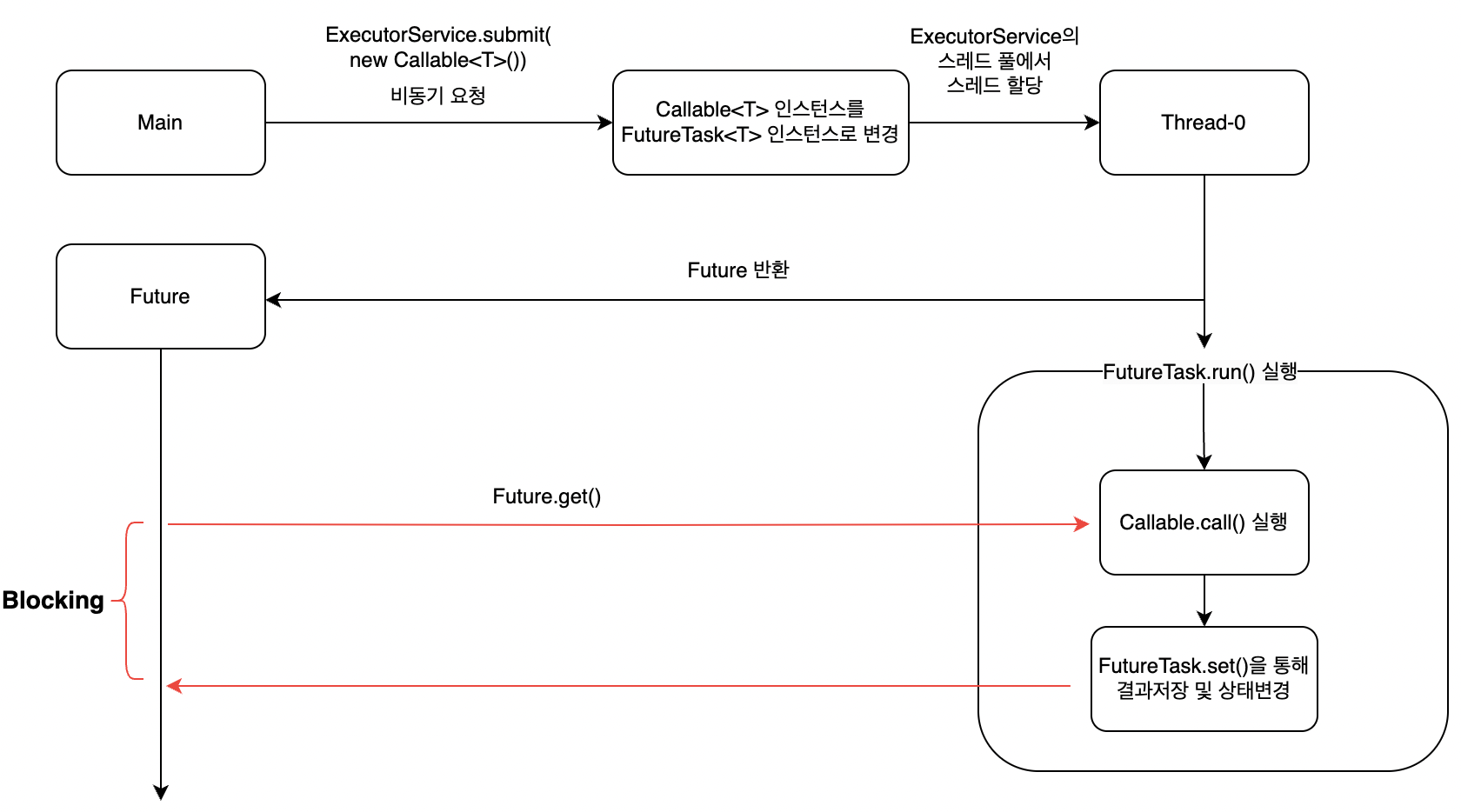
ExecutorService에서 Callable 작업을 제출하면, 내부적으로 FutureTask 인스턴스로 변경된다. FutureTask는 아래와 같은 특징이 있다.
- 생성자를 통해 Callable 인스턴스를 받는다.
- Runnable 인터페이스를 구현하고 있어서 스레드에서 직접 실행할 수 있다.
- Future 인터페이스도 구현하고 있어서 작업의 상태나 결과를 가져올 수 있다.
즉, FutureTask를 통해 작업의 실행 상태를 관리하고, Callable.call()의 결과를 저장한다. 그렇다면 비동기로 실행되는 작업이 Future라는 결과에 값을 받아오기까지의 과정을 디버깅을 통해 알아보자.
2.2.1 Main 스레드에서 ExecutorService.submit()을 통한 작업제출
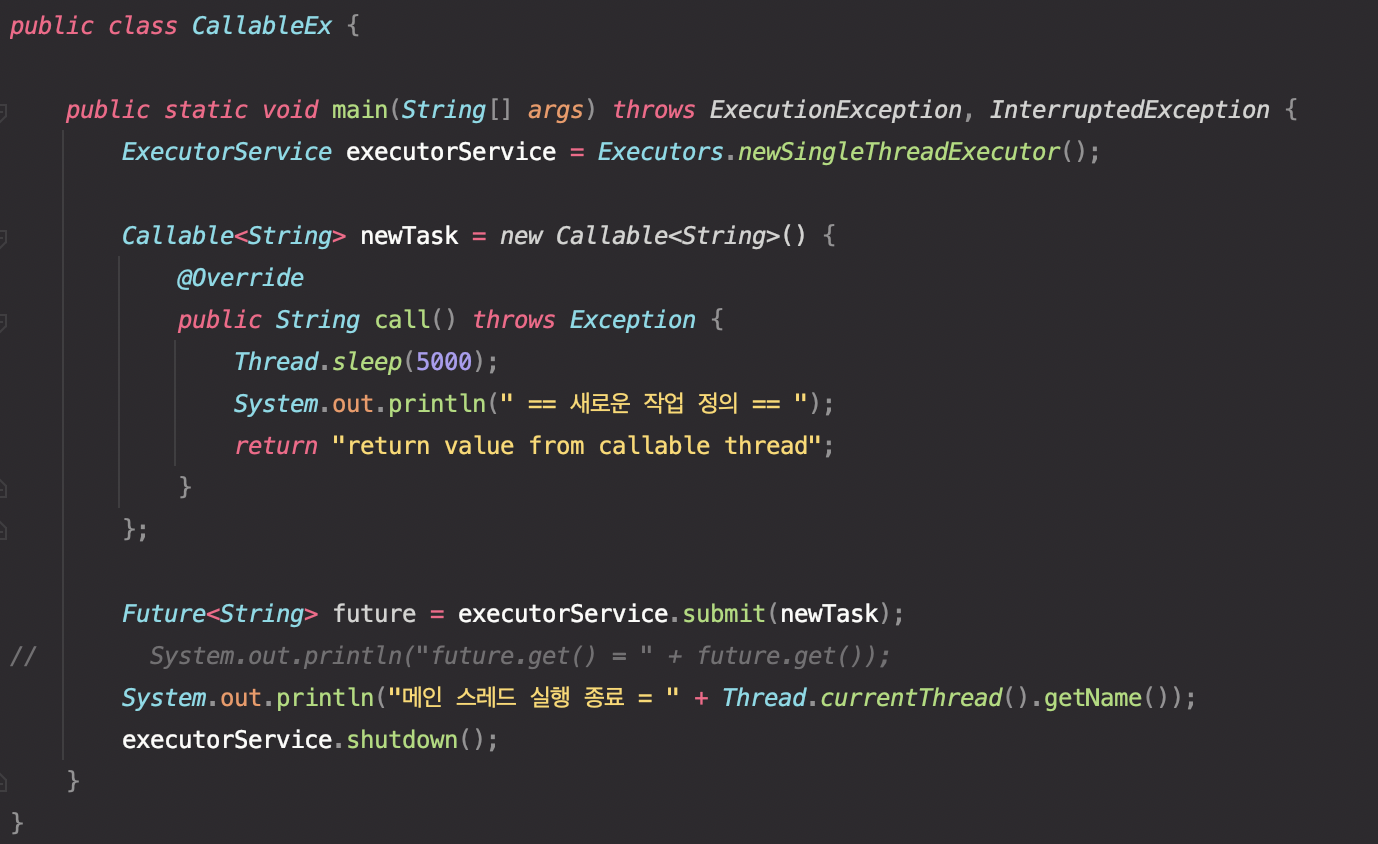
우선, future.get()메서드를 주석처리 하여 값을 가져오지 않는 경우부터 차근차근 살펴보자.
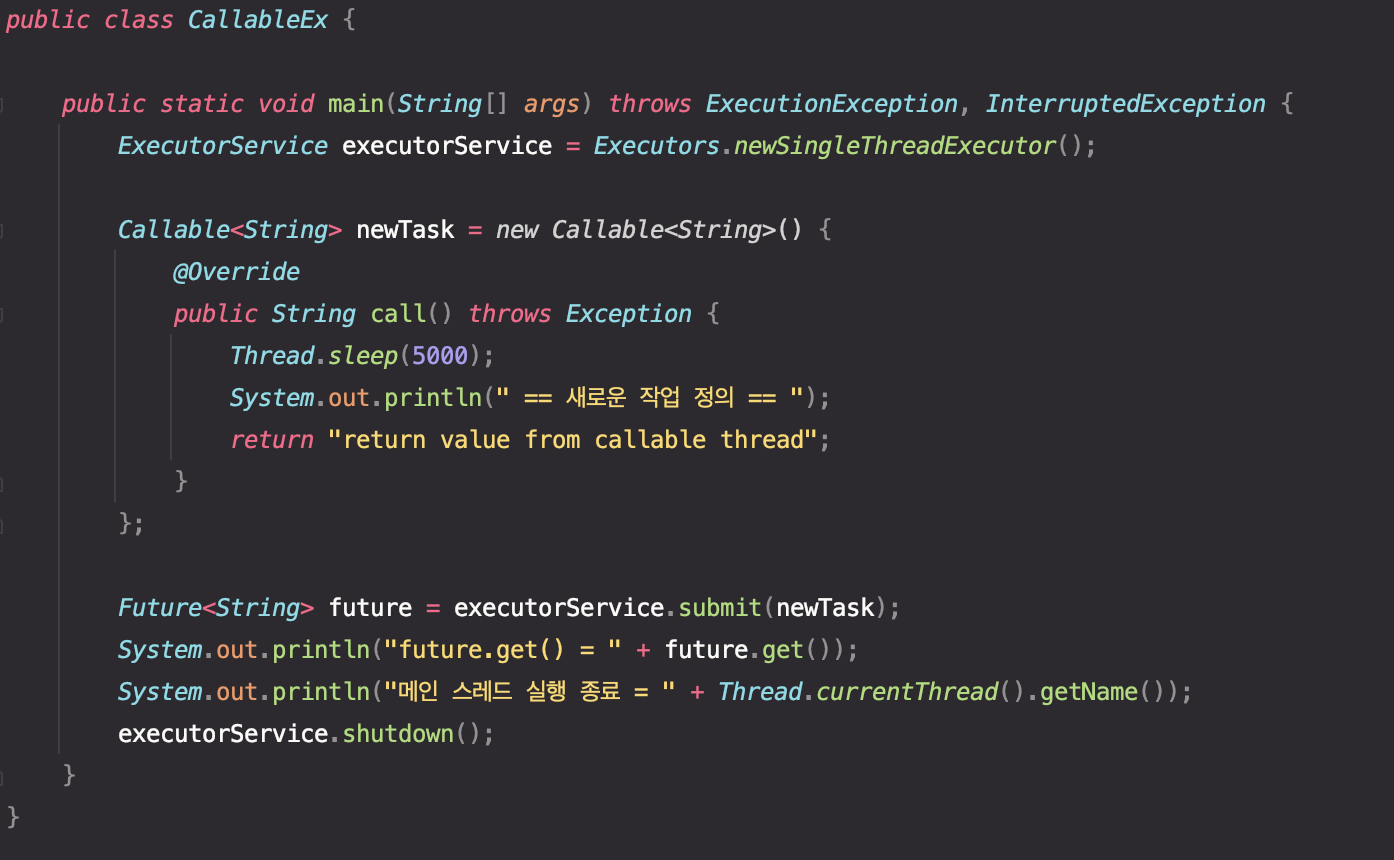
Main 스레드에서 Callable 작업을 정의하고, ExecutorService.submit()을 통해 작업을 제출하였다.
위 코드의 의도는 "메인 스레드 실행 종료" 이후에 "== 새로운 작업 정의 =="라는 결과가 나오는 것이다. 실행 결과는 아래와 같다.

다행히 의도대로 나온다. 즉, 비동기 처리가 의도한대로 이루어진것이다.
2.2.2 FutureTask 인스턴스 생성
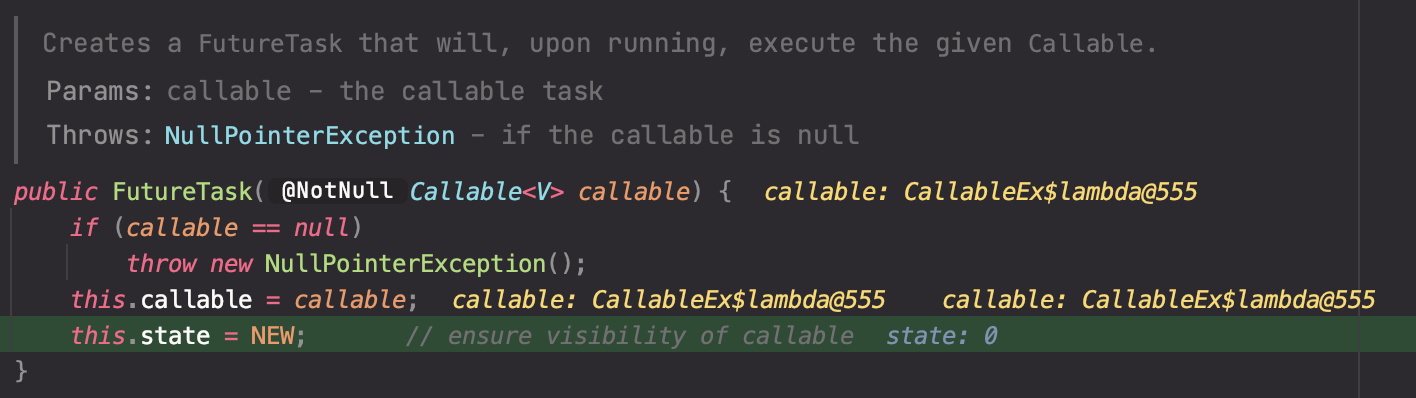
FutureTask의 생성자이다. callable에 정의한 태스크가 들어간 것을 확인할 수 있다. 동시에 FutureTask에서 관리하고 있는 state도 변경한다.
2.2.3 ExecutorService의 스레드 풀에서 새로운 스레드 할당
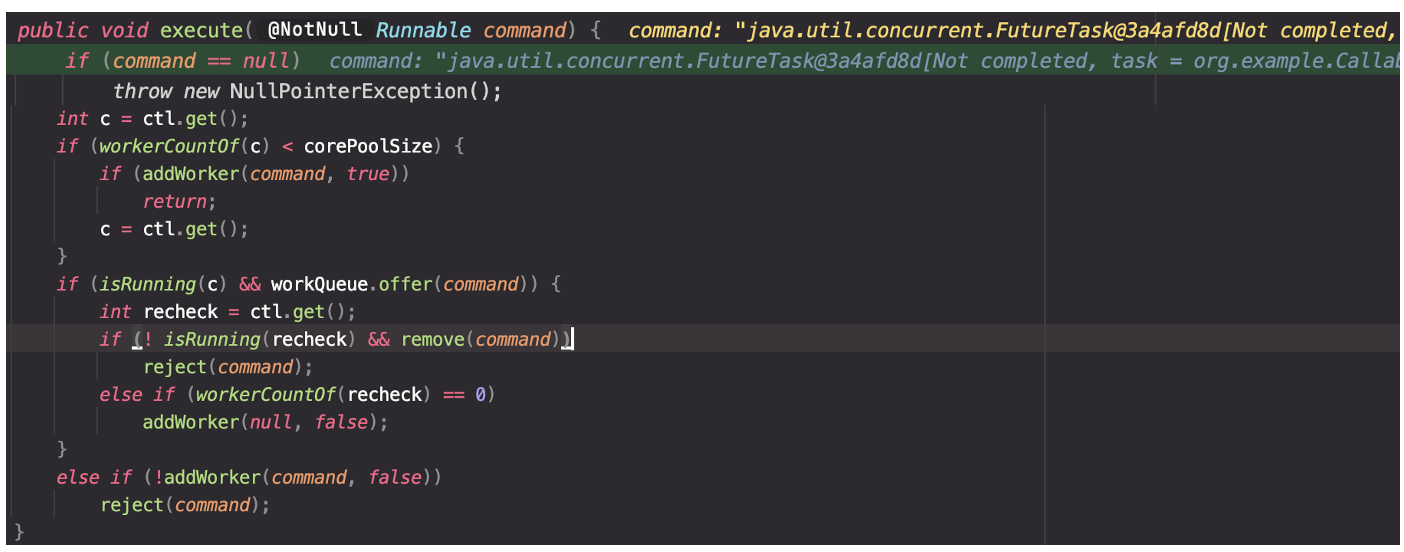
ThreadPooleExecutor의 execute()메서드는 아래와 같은 작업들을 수행한다.
-
새 스레드 시작 시도 (corePoolSize 검사): 실행 중인 스레드 수가 corePoolSize보다 작은 경우, 새로운 스레드를 시작하려고 시도한다. 이 새 스레드는 제출된 Runnable 태스크를 첫 번째 작업으로 실행한다. addWorker 메서드 호출은 스레드 풀의 상태와 현재 스레드 수를 원자적으로 검사하여, 필요하지 않은 경우에는 새로운 스레드를 추가하지 않는다.
-
작업 큐에 태스크 추가 시도: 태스크를 내부 작업 큐에 추가하려고 시도한다. 성공적으로 큐에 추가된 경우, 여전히 스레드를 추가해야 할 필요가 있는지 또는 스레드 풀이 종료 상태로 바뀌었는지를 다시 확인한다. 필요한 경우, 큐에 추가된 태스크를 롤백하거나 새로운 스레드를 추가한다.
-
새 스레드 추가 시도 (작업 큐가 가득 찬 경우): 태스크를 큐에 추가할 수 없는 경우 (즉, 큐가 가득 찬 경우), 새로운 스레드를 추가하려고 시도한다. 이 시도가 실패하면, 스레드 풀이 종료 상태이거나 포화 상태임을 의미하므로, 태스크를 거부한다.
즉, execute()메서드는 작업을 실행하기 위한 적절한 스레드를 생성하거나 할당한다.
2.2.4 FutureTask.run() 실행
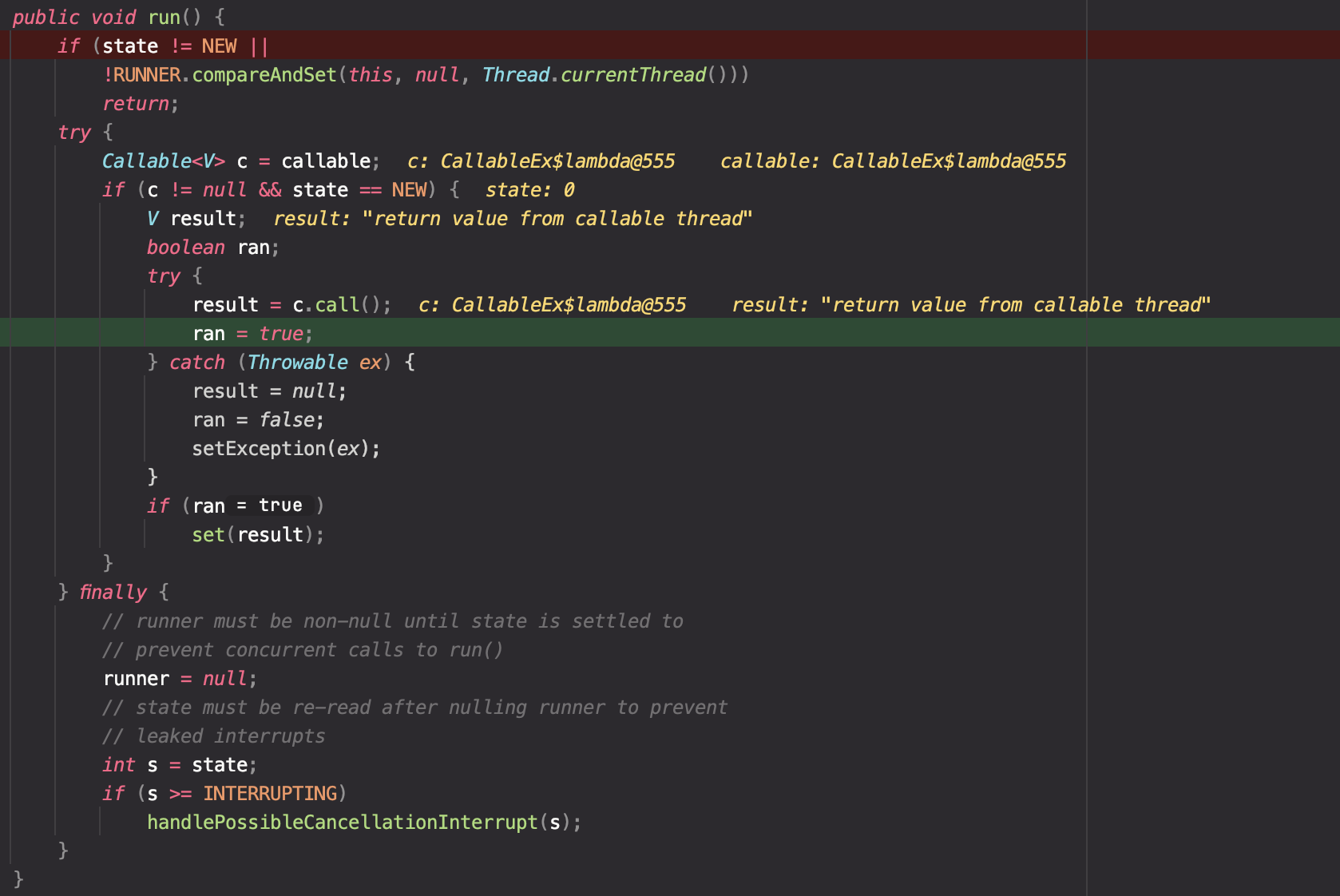
할당된 스레드는 FutureTask.run()을 실행한다. 수행 과정은 아래와 같다.
- FutureTask가 가지고 있는 callable 인스턴스를 통해 정의된 작업을 가져온 후, call()메서드를 통해 실제로 정의된 작업을 수행한다.
- 정의한 작업(2.2.1에서 작성한 코드)의 결과인 "return value from callable thread"가 result라는 변수에 저장된다.
- set() 메서드를 통해 결과값을 FutureTask 내부에 저장한다.

set()메서드를 통해 작업의 결과를 FutureTask 내부에 저장하고, 상태를 적절하게 변환시킨다. Main 스레드에서 Future.get()을 통해 결과를 받고자 할 때, 바로 이 "outcome" 객체를 리턴한다.
2.2.5 Future.get()을 통한 결과 가져오기
2.2.1(Future.get()을 주석처리)에서 정상적으로 비동기 처리가 된 결과를 확인했다. 이제 Future.get()을 통해 결과를 가져와보자.
future.get()을 통해 2.2.1 ~ 2.2.4 까지의 작업을 수행하고, FutureTask.get()을 통해 수행된 작업의 결과를 가져와 보았다.
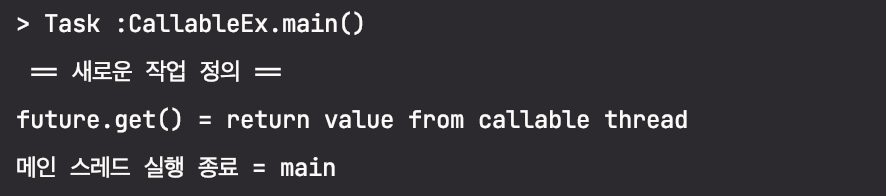
2.2.1에서 본 것과 달리 결과가 달라졌다. 바로 Future.get() 메서드가 그 이유인데, 실제 수행되는 메서드를 살펴보자.

FutureTask가 아직 완료되지 않았다면 awaitDone(false, 0L) 메서드를 호출하여 호출 스레드가 작업의 완료를 대기하도록 한다.
awaitDone() 메서드가 현재 스레드를 대기상태로 만들고, 타임아웃 없이 완료될 때까지 대기하기 위해 타임아웃 파라미터에 0을 넘기고 있다.
이렇게 Callable과 Future를 통해 어떤 식으로 비동기 작업을 수행하고, 결과를 저장하고 가져오는지에 대해 구조를 파악해봤다. 그런데, 비동기 태스크의 결과를 받아오기 위해서는 블로킹 상태를 거쳐야 한다는 것이었다. 그래서 Java8 이후에 등장한 CompletableFuture가 있다. 다시 한번 짚어보자. 근본적인 Future의 한계점은 비동기 연산의 완료를 기다려야 한다는 것이다.
3. CompletableFuture
CompletableFuture는 비동기 프로그래밍을 가능하게 하는 기능 중 하나이다. Future 인터페이스는 비동기 연산의 결과를 나타내긴 하지만, 연산이 끝날 때까지 get() 메서드를 통해 결과를 기다리는 블로킹 호출이다. CompletableFuture는 Future를 확장한 것으로 비동기 연산이 완료될 때까지 블로킹 되지 않고, 결과가 나오면 즉시 다음 작업을 계속할 수 있는 방법을 제공한다.
CompletableFuture의 주요 특징
- 비동기 콜백을 제공한다.
- 비동기 콜백 메서드는 논블로킹 연산이라는 특징을 가진다.
- 한번 생성된 CompletableFuture를 계속해서 재사용할 수 있어, 다중처리가 가능하다.
- 에러 핸들링을 우아하게 처리할 수 있는 방법을 제공한다.
이 글에서는 CompletableFuture가 내부적으로 어떤 구조를 가지고 있고, 어떻게 비동기 작업을 처리하는지, Future와는 다르게 어떻게 블로킹 방식이 해결되었는지를 정리하고자 한다.

CompletableFuture는 Future와 CompletionStage 인터페이스를 구현하고 있다.
CompletionStage?
CompletionStage 인터페이스는 Java 8에서 도입된 비동기 계산의 결과를 표현하며, 비동기 연산이 완료될 때 수행될 작업들을 연결할 수 있는 여러 메소드를 제공한다.
CompletableFuture에서 제공하는 메서드

CompletableFuture의 작업은 크게 세 가지로 분류할 수 있다.
-
비동기 작업 실행
runAsync()와 supplyAsync()가 여기에 포함된다. -
비동기 작업 콜백
thenApply(), thenAccept(), thenRun()이 여기에 포함된다. 모두 CompletionStage에서 제공하는 메서드인 것을 확인할 수 있다. 즉, 비동기 연산이 완료될 때 수행될 작업들을 연결할 수 있는 메서드들임을 의미한다. -
비동기 작업 조합 CompletionStage에서 제공하는 thenCompose(), thenCombine()과 CompletableFuture에서 제공하는 allOf()와 anyOf()가 여기에 해당한다.
비동기 작업이 내부적으로 어떻게 실행되는지 확인해보기 위해, supplyAsync()를 디버깅 해보면서 어떻게 스레드가 할당되고, 비동기로 동작하는지 알아보려고 한다.
3.1 supplyAsync() 동작 방식
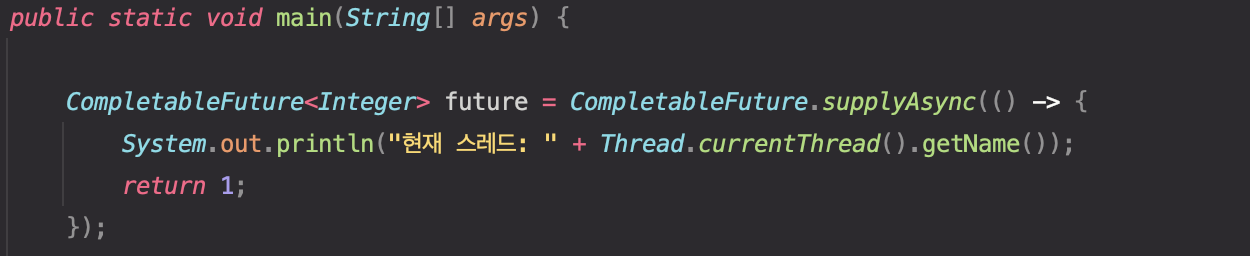 위와 같이 작성했다. 위에서 정리했듯 supplyAsync()의 인자는 Supplier이므로 람다로 표현하여 작성하였다.
위와 같이 작성했다. 위에서 정리했듯 supplyAsync()의 인자는 Supplier이므로 람다로 표현하여 작성하였다.
3.1.1 (main 스레드)
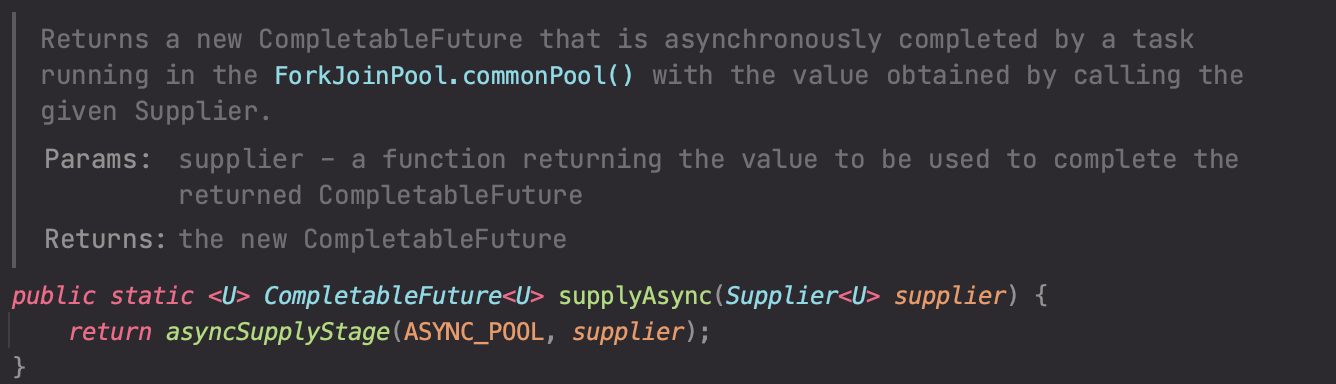
supplyAsync() 메서드의 설명을 빌리자면, ForkJoinPool로부터 스레드를 할당받아 태스크를 실행하고 비동기로 완료되는 값을 담은 CompletableFuture를 반환받는 것이다. supplyAsync()에서 호출하고 있는 메서드는 asyncSupplyStage()이다. 좀 더 알아보자. 우선, 상수로 정의되어 있는 ASYNC_POOL에 대해 알아보자.
3.1.2 (main 스레드)
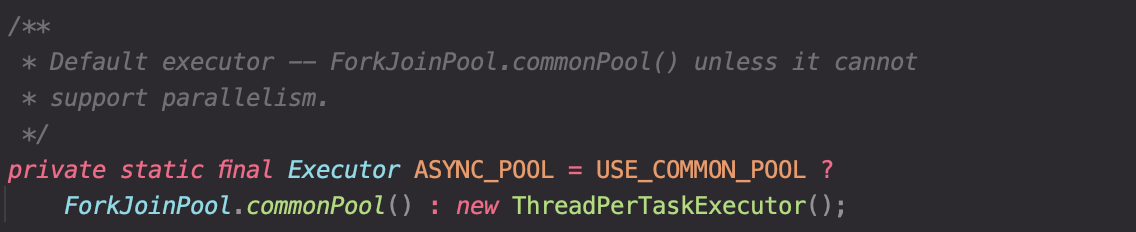
비동기 작업을 실행할 때 사용될 Executor를 정의하는 것으로, default로 ForkJoinPool에서 작업이 실행된다. (ForkJoinPool은 병렬 프로그래밍을 위한 고성능 스레드 풀이다. Future에서 사용한 ExecutorService인터페이스를 통해 제공되고 관리되는 스레드풀과는 다른방식의 스레드 풀)
즉, ForkJoinPool을 가져와서 정의한 작업(Supplier)와 함께 asyncSupplyStage()의 인자로 넘긴다. asyncSupplyStage()에 좀 더 들어가보자.
3.1.3 (main 스레드)

asyncSupplyStage() 내부에서 CompletableFuture 객체를 생성한 후, AsyncApply 라는 클래스의 생성자에 태스크와 함께 넘기는 것을 확인할 수 있었다. 그리고, Executor의 execute()메서드를 실행시킨다. 디버깅 해본 결과 ForkJoinPool의 execute()메서드를 실행 시키는데, CompletableFuture객체와 Supplier(정의한 작업)으로 만든 AsyncSupply 객체를 인자로 넘기는 것을 확인할 수 있었다. AsynSupply로 좀 더 들어가보자.
3.1.4 (main 스레드)
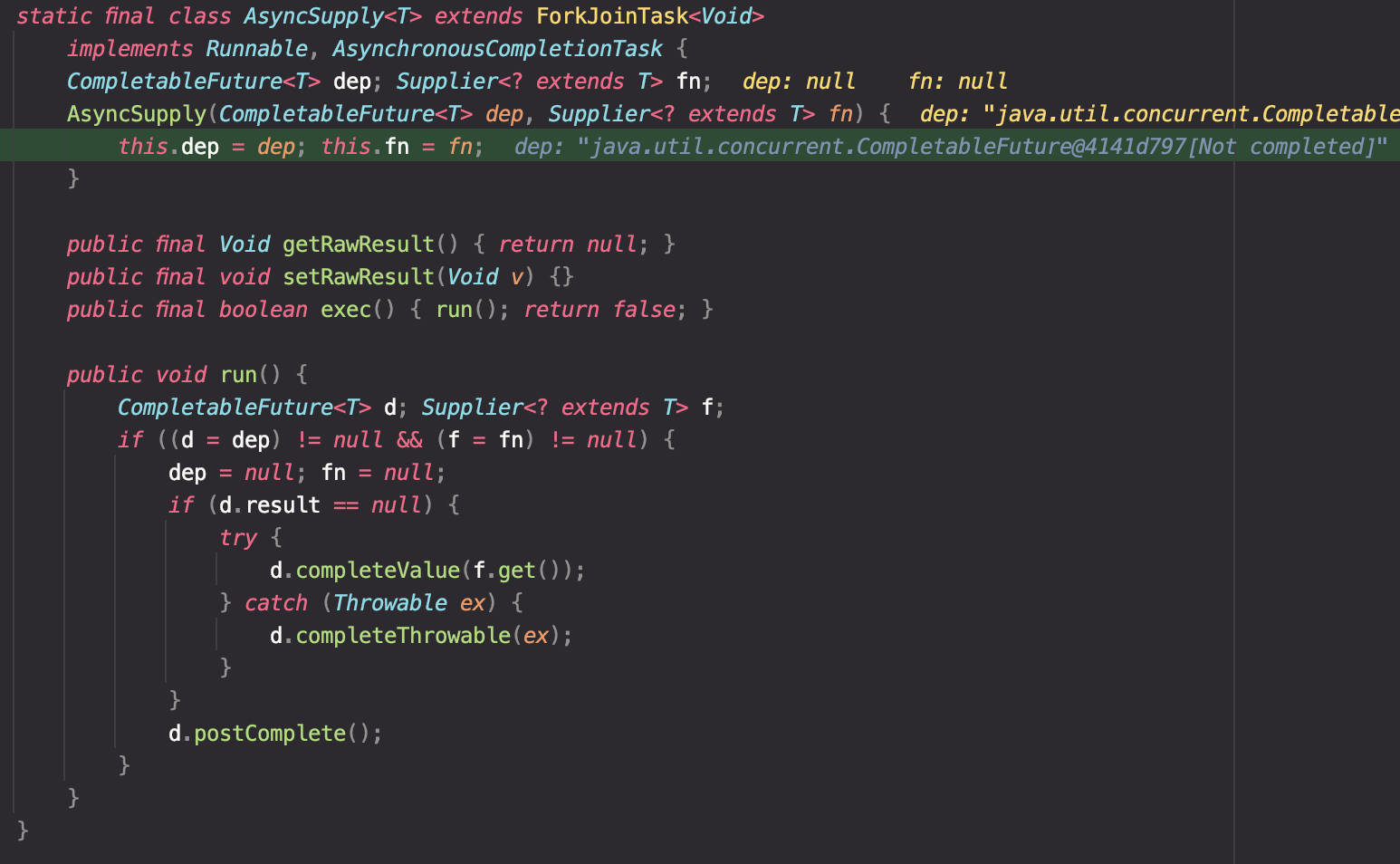
AsyncSupply 클래스는 ForkJoinTask를 상속받은 클래스로, 3.1.3에서 전달받은 CompletableFuture와 Supplier를 인자로 받아 생성한다. 그 외에도 run()메서드가 있다. 뒤쪽에서 설명하겠지만 이 run()메서드가 바로 ForkJoinPool로부터 별도로 생성된 스레드가 실행하게 되는 메서드이다.
이런식으로 메인 스레드는 CompletableFuture를 생성하고, AsyncSupply에 이 CompletableFuture와 작업 task를 넘기고, CompletableFuture를 반환한다. (사실, 메인 스레드가 ForkJoinPool의 execute()메서드를 실행시킴으로써 내부에서 Supplier 기반의 작업이 ForkJoinTask로 변환되어 작업 큐(WorkQueue)라는 곳에 작업을 저장하는 역할까지 수행한다.)
3.1.5 (ForkJoinPool.commonPool-worker)
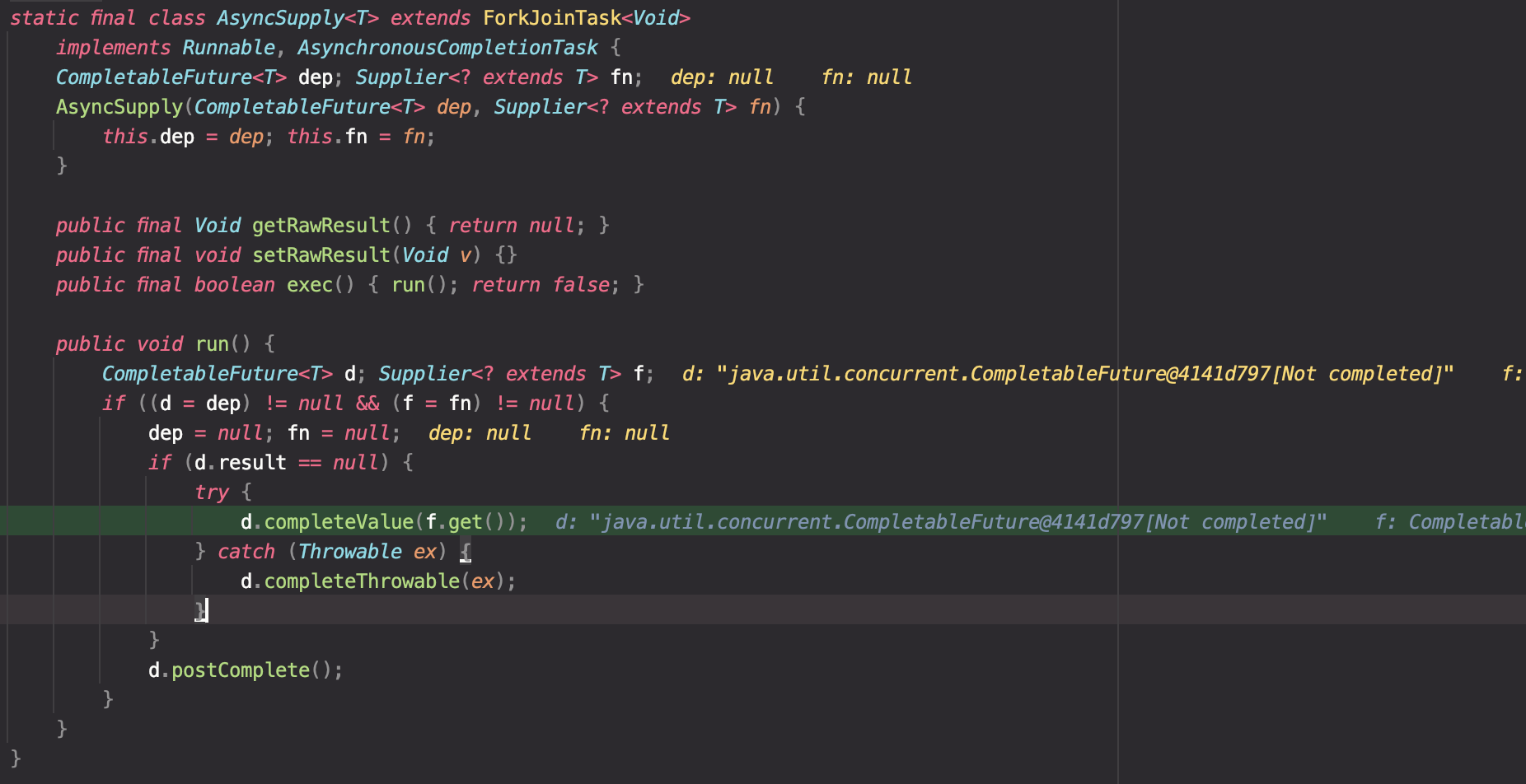
ForkJoinPool로부터 main스레드와 비동기로 처리되기 위한 별도의 스레드가 AsyncSupply.run()을 실행한다. Supplier.get()(f.get())을 통해서 작업결과를 가져와 CompletableFuture 객체에 넣어주는 것을 확인할 수 있었다.
3.2 supplyAsync 실행 흐름도
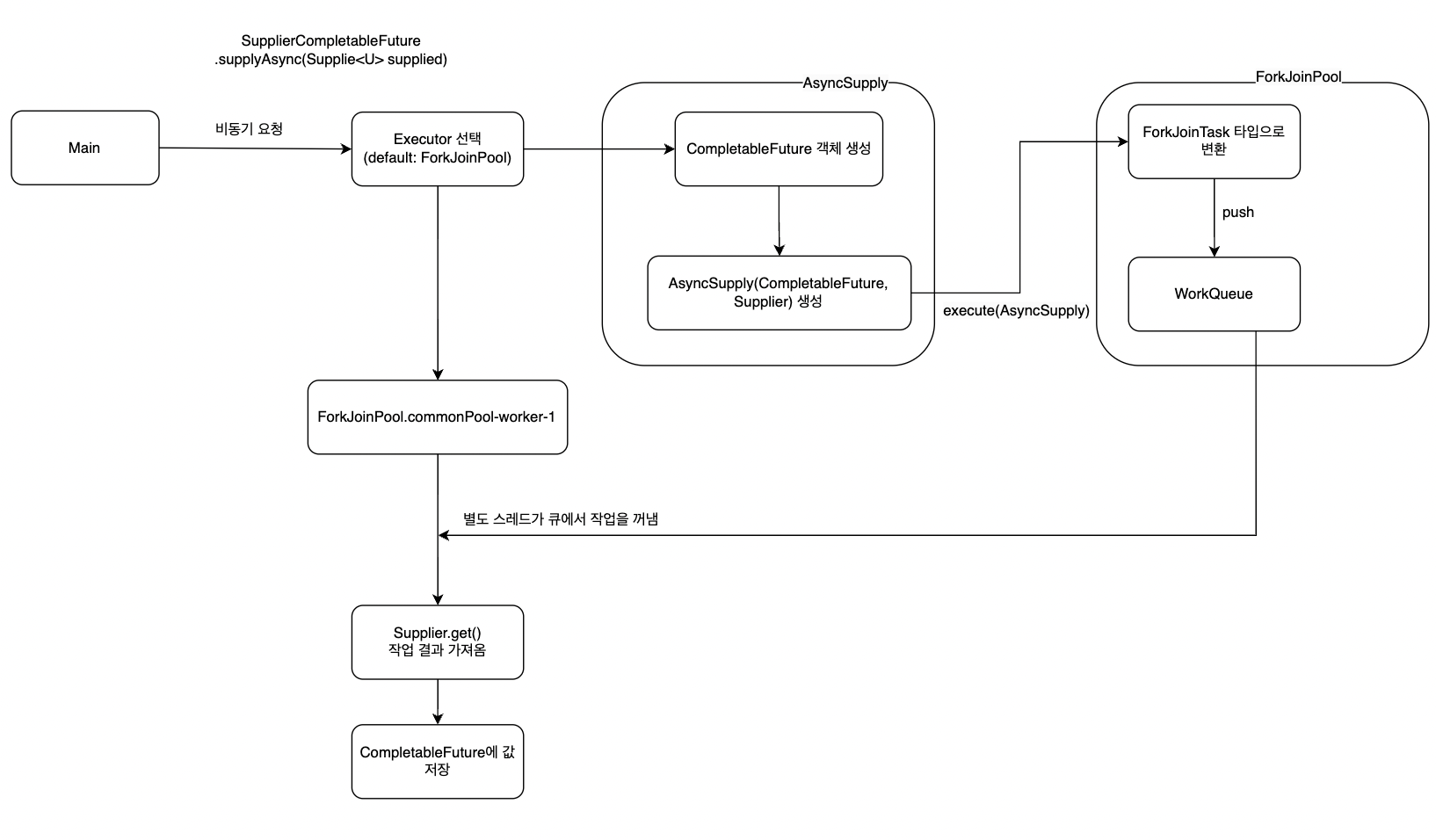
3.1에서 디버깅을 통해 알아본 supplyAsync() 동작 방식에 대한 구성이 위와 같다는 것을 확인할 수 있었다.
[참고 자료]
https://mangkyu.tistory.com/263